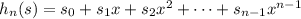 для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)
для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)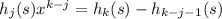 – проверить это быстрее, чем ходить циклом.
– проверить это быстрее, чем ходить циклом.Объяснение:
const
max_elements = 1000;
a = 1;
b = 15;
first_file_name = '1.txt';
second_file_name = '2.txt';
var
i, j, n, r:integer;
p:real;
ar:array[1..max_elements] of integer;
f1, f2:text;
begin
randomize;
writeln('Input n = ');
readln(n);
for i:=1 to n do begin
ar[i]:=random(b-a+1)+a;
end;
assign(f1, first_file_name);
rewrite(f1);
for i:=1 to n do begin
writeln(f1, ar[i]);
end;
close(f1);
assign(f2, second_file_name);
rewrite(f2);
for i:=1 to n do begin
p:=1;
for j:=1 to i do
p:=p*ar[j];
writeln(f2, p:0:0);
end;
close(f2);
readln;
end.