Можно поступить следующим образом: создаем multimap. Читаем слова из словаря, для каждого слова находим все супрефиксы, вставляем их в multimap в качестве ключа, значение можно ставить любое (например, (int) 1). После этого в цикле читаем слова-образцы и выводим значение count от каждого слова-образца.
Программа будет иметь примерно такую структуру: multimap<string, ...> subprefixes input n n times: input s for j = 0..size of s: if s[..j] is subprefix of s: subprefixes.insert(pair<string, ...>(s[..j], ...)) input m m times: input s print subprefixes.count(s)
Остался вопрос, как определять, является ли s[..j] супрефиксом. Конечно, можно это делать наивно: пройти циклом для всех возможных длин подстрок j и проверить, правда ли, что s[0] = s[s.size() - j - 1], s[1] = s[s.size() - j]...
Как можно ускорить всё это? 1) Выберем какое-нибудь достаточно большое (по сравнению с кодами символов) простое число x, например, x = 1009. Вычислим для строки s все хеши по формуле для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50) Теперь если у строки s длины k есть супрефикс длины j, то обязательно – проверить это быстрее, чем ходить циклом. 2) Необязательно хранить в multimap-е подстроки, это дорого и по времени и по памяти. Можно хранить хеши. 3) Можно вместо одного multimap-а создать 50 multimap-ов, в каждом хранить только супрефиксы одной длины.
Получаем примерно такое: pow = new long long[51] pow[0] = 1 for i = 1..50: pow[i] = x * pow[i - 1] suprefixes = new multimap<long long, ...>[51] input n n times: input s h = hashes(s) k = len s for j = 1..k: if h[j] * pow[k - j] == h[k] - h[k - j - 1]: suprefixes[j].insert(pair(h[j], ...)) input m m times: input s print puprefixes[len s].count(hash(s))
В принципе, для такого решения multimap не нужен, достаточно иметь map, и хранить для каждого ключа количество вхождений. Это можно делать и для multimap.
270 - это ответ, чтобы добраться до него, нужно 1. Рассмотреть варианты когда в шифре две единицы, а остальные любые цифры. По условию у нас длинна шифра 5, и используем символы 1,2,3,4. Теперь выделяем из длинны 5 два места под единицы, остается длинна 3, в которую нужно поместить все сообщения состоящие из 3 цифр (2,3,4 - т.к. единицу уже использовали) По формуле Q = M в степени K, где Q - сколько сообщений получится, M - количество используемых символов (у нас исп. 2,3,4, т.е. 3 символа), а K - длинна сообщений (мы ищем длину сообщений 3 буквы, т.к. 2 у нас уже заняты единицами) найдем М. М = 3 в степени 3, т.е. М = 27.Получаем, что в одном таком варианте 27 разных сообщений. 2. Выше мы рассмотрели только один вариант, где 2 единицы стояли на двух первых местах, т.е 11ххх, где ххх - это цифры 2.3.4. Чтобы понять сколько таких вариантов существует, используем формулу сочетаний из n по k (в нашем случае из 5 по 2) она равна 5!/2!*(5-2)!=10. Получаем что есть 10 вариантов расстановки 2-х единиц в сообщении длинной 5, можно даже перебрать все 10 вариантов (1. 11ххх 2.1х1хх 3. 1хх1х 4. 1ххх1 5. х11хх 6. хх11х 7. ххх11 8. х1х1х 9. хх1х1 10. 1ххх1)
Подведем итог, 10 вариантов по 27 сообщений - итог 270 сообщений.
0,0(0 оценок)
Полный доступ
Позволит учиться лучше и быстрее. Неограниченный доступ к базе и ответам от экспертов и ai-bota
Оформи подписку
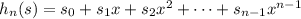 для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)
для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)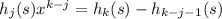 – проверить это быстрее, чем ходить циклом.
– проверить это быстрее, чем ходить циклом.